_main
Variables can be accessed either as part of a dataset, by their dtype, or individually.
# To access the entire dataset:
ix.eda(titanic)
# Alternatively, to access specific variables by their dtype:
ix.eda(titanic, val='text')
# Alternatively, to access the 'Age' variable individually:
ix.eda(titanic, 'Name')

Statistical Information on the Variable
| VALID | Percentage of valid observations in the variable |
| MISSING | Percentage of missing observations in the variable |
| UNIQUE | Percentage of unique observations in the variable |
The mini bar chart shows the variable value distribution (it uses log-scale making variations more apparent)
Stats
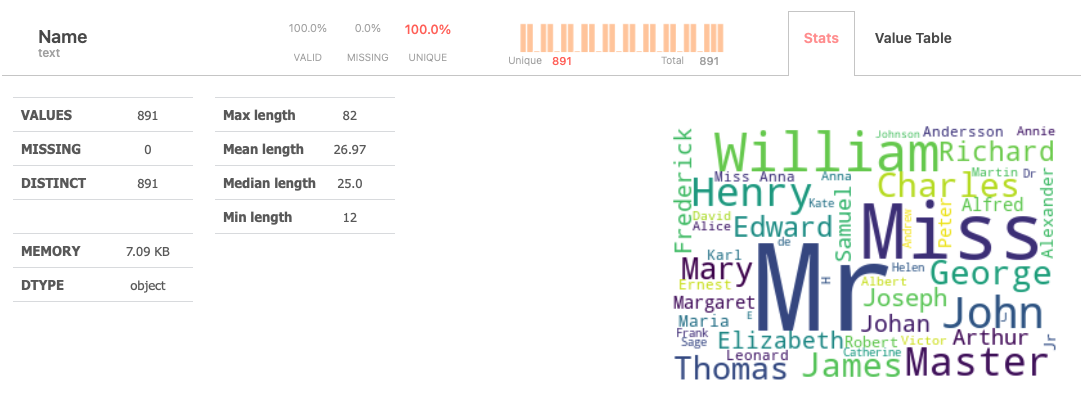
The “Stats” tab provides users with an extensive set of statistics.
Additionally, the tab includes a favorite word cloudvisualization highlighting popular terms within the variable’s distribution.
| VALUES | Number of valid values in the variable |
| MISSING | Number of missing observations in the variable |
| DISTINCT | Number of unique observations in the variable |
| MEMORY | Memory size of the variable |
| DTYPE | Pandas datatype |
| Max length | Length of the longest value |
| Mean length | Average length of all values |
| Median length | Middle value among all lengths |
| Min length | Length of the shortest value |
Value Table
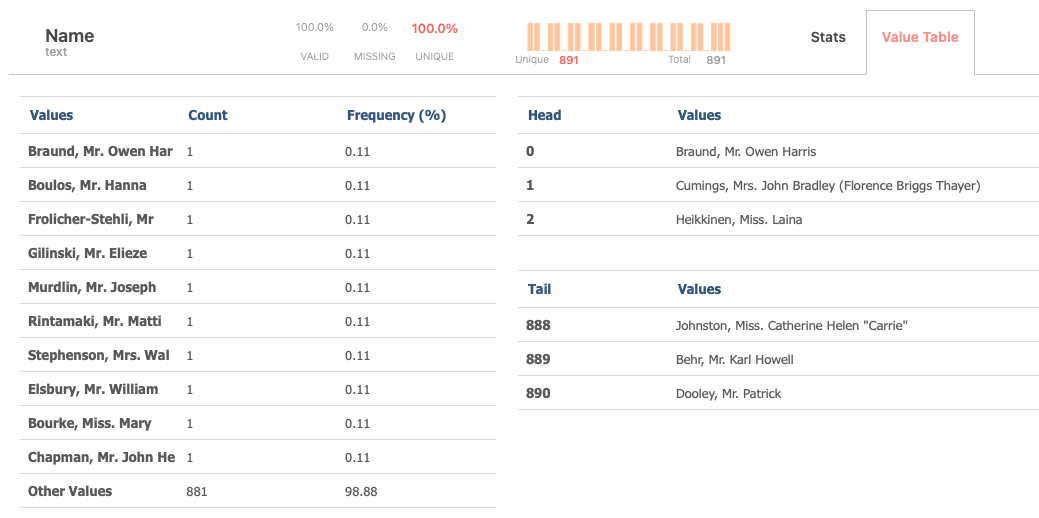
The value table organizes data by sorting values according to their frequency of occurrence, enabling quick identification of the most common values (up to 10) within the dataset.
And additionaly displaying the top three and bottom three values for quick reference and analysis.