General Configuration
Recognizing that data preparation consumes significant time, the primary focus of ADIX is to streamline the analysis process for users. Consequently, extensive configuration options are intentionally kept to a minimum to avoid impeding the workflow.
However, users still have the flexibility to customize certain aspects, such as the color theme palette. Furthermore, options to disable the cache or the dashboard panel or manually override the dtypes are available for those seeking additional control over their experience.
Themes
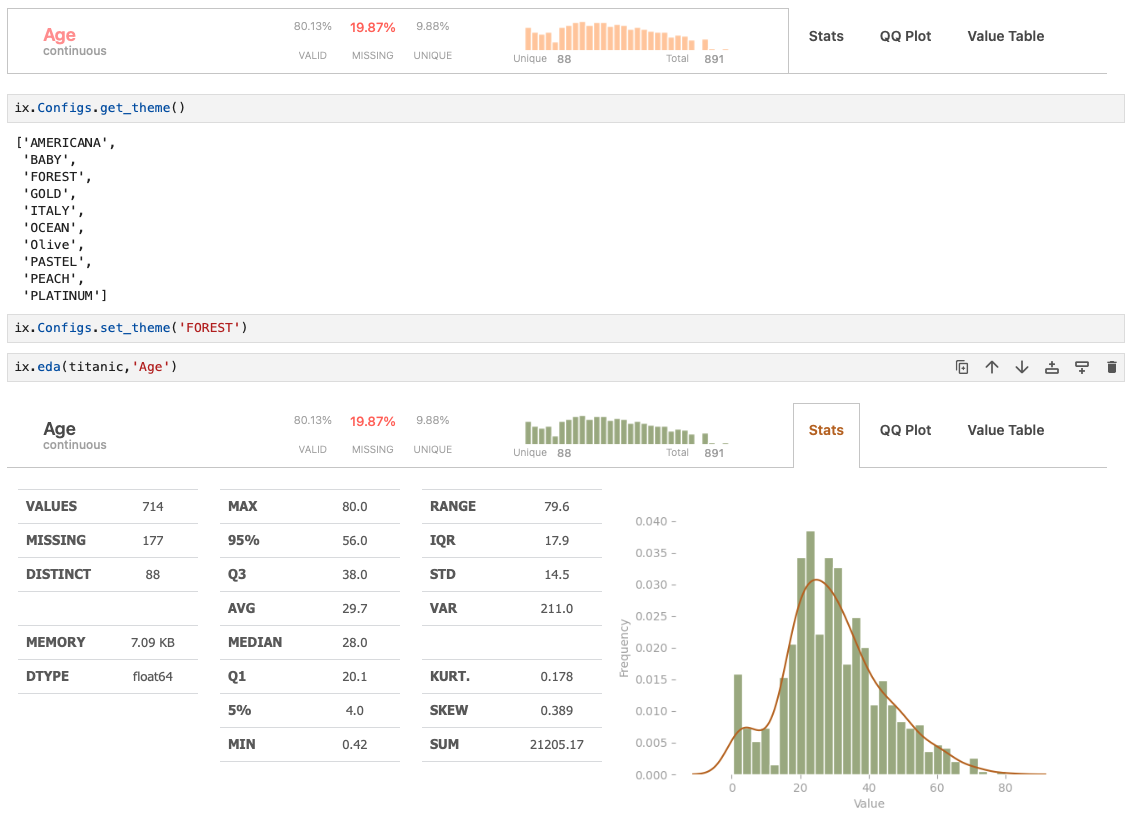
Easily adjust the visualization theme to match your preferences. You can either select from pre-prepared theme plates by calling two functions .get_theme() & .set_theme() or customize ADIX with your own color palettes. Check out the documentation/Themes section for detailed instructions:
ix.Configs.get_theme()
# Explore available themes and set your preferred one
ix.Configs.set_theme('FOREST')
Cache
ADIX employs caching as its default mechanism for a simple reason: it significantly accelerates the reloading of dataframes and visualizations, up to 10x times faster!
The system is intelligent enough to detect changes in dataframes and adapt accordingly. It’s highly recommended to keep caching active primarily for performance reasons. However, you can disable it easily by entering:
# Disable cache
ix.Configs.use_eda_cache = false
Dashboard
The Dashboard serves as a swift initial insight into the dataset. By default, it appears when loading the entire dataset and is disabled when accessing individual variables or employing bivariate relations.
As previously mentioned, since the entire dataframe is cached, attempting to deactivate it for time-saving purposes is computationally inefficient. Nonetheless, you can still disable it by entering:
# Disable dashboard
ix.eda(df,dash=False)
If you’d like to render dashboard solely, use ‘only’.
# Disable dashboard
ix.eda(df,dash='only')
Dtypes
The ADIX package offers a robust solution for data preprocessing by automatically determining data types, categorizing variables into continuous, categorical, text, and datetime types.
This automated approach streamlines the initial stages of data analysis, saving time and effort. However, given the complexity and variability of datasets, there may be instances where the automated categorization process may misclassify variables.
In such cases, ADIX provides users with functions to manually adjust the data types as needed. These functions empower users to fine-tune the data preprocessing pipeline, ensuring accurate and reliable analysis results tailored to the specific requirements of their datasets.
# get the suggested dtypes for the dataframe
ix.Configs.get_dtype(df)
# set your suggested dtypes for the dataframe
ix.Configs.set_dtype(df, dtypes_dict)